

はじめに
こんにちは。
最近は「Rによるセイバーメトリクス入門」を使って勉強しています。
この本ではLahmanというMLBデータのパッケージを使って様々な角度からセイバーメトリクスを解説しています。筆者にとっては少し難しいのですが、色々な学びがあります。
今回は、この中の「選手の成績推移」という章に関して、NPB(日本のプロ野球)データを使って遊んでみようと思います。
まずは個人の打撃成績の推移を見た後、その通算成績から類似した選手を比較することをしていきたいと思います。
データの取得
以前も書いたのですが、NPBってまとまったデータベースなどが公式にはないんですよね。なので、コチラを参考にさせていただき、NPBのデータを作成しました。
自分の環境では最後の方の右打ちや左打ちの変数を追加するところがうまくいかなかったので、その辺りを省いたデータになっています。
参考までに、使用したデータを置いておきます。
打撃成績推移
それでは、平成唯一の三冠王、松中信彦選手に注目して、その打撃成績推移を見ていきましょう。
まずはtidyverseパッケージを読み込み、先ほど作成したbattingデータを使います。(上記の方法でデータ取得を行うと、dataフォルダが作成され、その下にbatting.csvができます。)
library(tidyverse)
batting <- read_csv("data/batting.csv")
個人の打撃成績をまとめるためにget_stats関数を作成します。get_stats関数には年齢、SLG(長打率)、OBP(出塁率)、OPS(出塁率+長打率)が含まれます。
get_stats <- function(Player.id){
batting %>%
filter(PlayerID == Player.id) %>%
select(Age, SLG, OBP, OPS)
}
次に、松中信彦選手のPlayerIDを取得し、それを先ほど作成したget_stats関数を使って個人の打撃成績のデータフレームを作成します。ざっくりとした打撃能力を把握するためのOPSを指標に散布図で表現します。
batting %>% #PlayerID取得
filter(grepl("Nobuhiko Matsunaka", Name)) %>%
pull(PlayerID) %>%
head(1)-> matsunaka_id
Matsunaka <- get_stats(matsunaka_id) #get_stats関数
ggplot(Matsunaka, aes(Age, OPS)) + geom_point() #OPSの散布図
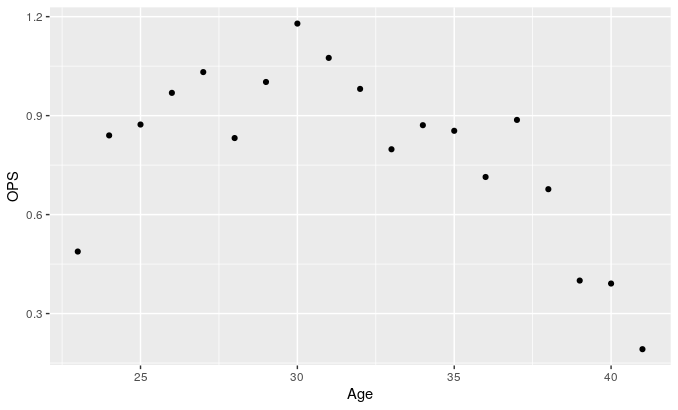
このグラフを見ると、30歳まで増加しており、それ以降は急激な低下が見て取れます。この浮き沈みを滑らかな曲線でモデリングしていきます。曲線を使うことで、その後の要約などがしやすくなり、打撃成績の比較がしやすくなります。
筆者自身数学が苦手なので、細かい数式の理解などはできていないのですが、以下のような二次関数で滑らかな曲線を表現できるようです。
A + B(Age - 30) + C(Age - 30)2
これを使って関数を作成します。また、その結果からピーク時の年齢とOPSの最大値を算出します。
fit_model <- function(d){
fit <- lm(OPS ~ I(Age - 30) + I((Age - 30)^2), data = d)
b <- coef(fit)
Age.max <- 30 - b[2] / b[3] / 2
Max <- b[1] - b[2]^2 / b[3] / 4
list(fit = fit, Age.max = Age.max, Max = Max)
} #曲線を作成するための関数
F2 <- fit_model(Matsunaka) #fit_model関数に松中選手を入力
coef(F2$fit)
c(F2$Age.max, F2$Max) #ピーク時の年齢とOPSの最大値を算出
coef(F2$fit)
(Intercept) I(Age - 30) I((Age - 30)^2)
1.026239334 0.004198629 -0.007125534
c(F2$Age.max, F2$Max)
I(Age - 30) (Intercept)
30.294619 1.026858
これらの結果から、次式の時に曲線の当てはまりが最も良くなるとわかります。
1.026239334 + 0.004198629(Age - 30) - 0.007125534(Age - 30)2
また、ピーク時の年齢は30歳、OPSの最大値は1.026858と推定されます。
ではこの曲線を図示していきましょう。
ggplot(Matsunaka, aes(Age, OPS)) + geom_point() +
geom_smooth(method = "lm", se = FALSE, size = 1.5,
formula = y ~ poly(x, 2, raw = TRUE)) +
geom_vline(xintercept = F2$Age.max,
linetype = "dashed", color = "darkgrey") +
geom_hline(yintercept = F2$Max, linetype = "dashed", color = "darkgrey") +
annotate(geom = "text", x = c(29, 20), y = c(0.72, 1.1),
label = c("Peak age", "Max"), size =5)
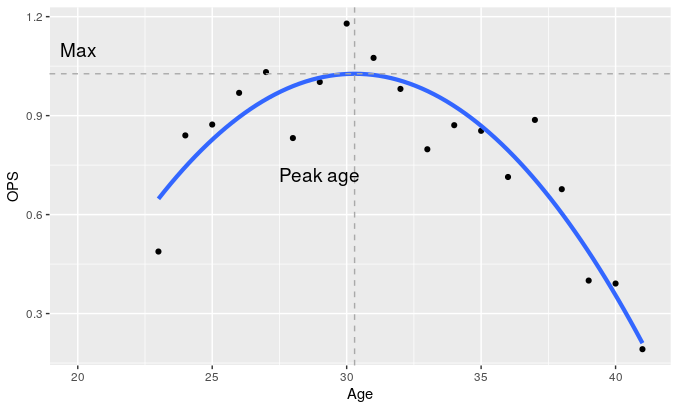
曲線があるほうが成績の推移が理解しやすくなりますね。いやしかし30歳の時のOPSの外れ値具合がえげつないですね…
成績推移の比較
では次に、松中選手に似たような選手を探していくことをしていきましょう。原著では、ポジションも考慮して類似性スコアというものを算出しているのですが、今回作成したデータベースではポジションの情報はありませんので純粋な打撃成績のみの比較になることを予めご理解ください。
事前準備
キャリアが短い選手も多いので、通算打数で分析対象選手を絞っていきます。今回は原著に合わせて、通算打数が2000打数以上の選手に絞ります。以下のコードを使って、通算打数が2000打数以上の選手のデータフレーム batting_2000 を作成します。
batting %>%
group_by(PlayerID) %>%
summarise(Career.AB = sum(AB, na.rm = TRUE)) %>%
inner_join(batting, by = "PlayerID") %>%
filter(Career.AB >= 2000) -> batting_2000
通算成績の計算
batting_2000 から選手ごとの通算成績を計算したデータフレーム(C.totals)を作成します。また、通算打率(AVG)と通算長打率(SLG)を計算して追加します。
vars <- c("G", "AB", "R", "H", "2B", "3B",
"HR", "RBI", "BB", "SO", "SB")
batting %>%
group_by(PlayerID) %>%
summarise_at(vars, sum, na.rm = TRUE) -> C.totals #通算成績の計算
C.totals %>%
mutate(AVG = H / AB,
SLG = (H - `2B` - `3B` - HR + 2* `2B` + 3 * `3B` + 4* HR) / AB) -> C.totals #AVGとSLGの追加
類似性スコアの計算
Bill Jamesという方が概念を取り入れた類似性スコアというものがあります。持ち点1000ポイントから、各指標の値に基づくポイントを差し引くことで2選手の類似度を算出するそうです。
類似性スコアを計算するsimilar関数を作成します。引数には選手固有のPlayerIDと、出力したい類似した選手の人数を入力します。
similar <- function(p, number = 10){
C.totals %>% filter(PlayerID == p) -> P
C.totals %>%
mutate(sim_score = 1000 -
floor(abs(G - P$G) / 20) -
floor(abs(AB - P$AB) / 75) -
floor(abs(R - P$R) / 10) -
floor(abs(H - P$H) / 15) -
floor(abs(`2B` - P$ `2B`) / 5) -
floor(abs(`3B` - P$ `3B`) / 4) -
floor(abs(HR - P$HR) / 2) -
floor(abs(RBI - P$RBI) / 10) -
floor(abs(BB - P$BB) / 25) -
floor(abs(SO - P$SO) / 150) -
floor(abs(SB - P$SB) / 20) -
floor(abs(AVG - P$AVG) / 0.001) -
floor(abs(SLG - P$SLG) / 0.002)) %>%
arrange(desc(sim_score)) %>%
head(number)
}
松中選手と似た選手を5人見つける場合は以下のように入力します。
similar(matsunaka_id, 6)
# A tibble: 6 x 15
PlayerID G AB R H `2B` `3B` HR RBI BB SO SB AVG SLG
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 matsun0… 1780 5964 972 1767 330 15 352 1168 857 909 28 0.296 0.534
2 kakefu0… 1625 5673 892 1656 250 31 349 1019 819 897 49 0.292 0.531
3 takaha0… 1819 6028 890 1753 297 9 321 986 634 1173 29 0.291 0.503
4 hara--0… 1697 6012 931 1675 273 25 382 1093 705 894 82 0.279 0.523
5 kato--0… 2028 6914 1031 2055 367 37 347 1268 807 1067 136 0.297 0.512
6 ramire0… 1744 6708 866 2017 328 12 380 1272 308 1259 20 0.301 0.523
# … with 1 more variable: sim_score <dbl>
PlayerIDを見ると、松中選手とは掛布選手や原選手などが似ているということがわかります。
次はこれを先程のように曲線を含めて図示して、もう少しわかりやすくしていきます。
成績推移に対するフィッテイングとプロット
引数に選手名、比較したい選手の数、出力グラフの列数を入力することで、各選手に対して二次曲線をフィッティングし、さらにわかりやすくグラフ化してくれるplot_trajectories関数を作成します。
plot_trajectories <- function(player, n.similar = 5, ncol) {
batting %>%
filter(grepl(player, Name)) %>%
select(PlayerID) -> player
player.list <- player %>%
pull(PlayerID) %>%
similar(n.similar) %>%
pull(PlayerID)
batting_2000 %>%
filter(PlayerID %in% player.list) -> Batting.new
ggplot(Batting.new, aes(Age, OPS)) +
geom_smooth(method = "lm",
formula = y ~ x + I(x^2),
size = 1.5) +
facet_wrap(~ Name, ncol = ncol) + theme_bw()
}
これを使って松中選手に似た8人の成績推移を見ていきます。
dj_plot <- plot_trajectories("Nobuhiko Matsunaka", 9, 3)
dj_plot
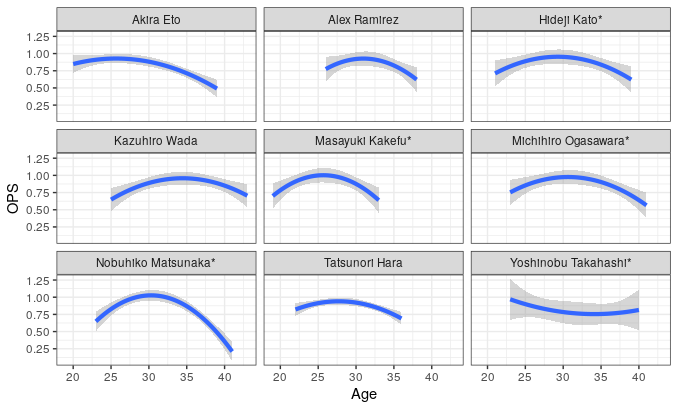
素晴らしい名選手ばかりが上がっていますね。ただ、類似性スコア上では似ていても、成績の推移にはそれぞれに違いがあります。
- 松中選手はキャリアとしては長いが、ピーク後の成績の降下が大きい。小笠原道大選手や和田一浩選手などは比較的なだらかである。高橋由伸選手に至っては、やや逆U字を描いている。
- 掛布雅之選手などはピークがかなり若くにあることがわかる。掛布選手だけでなく、アレックスラミレス選手や原辰徳選手はキャリアが比較的短いことがわかる(ラミレス選手は外国人ですしね)。
では具体的なピーク時の年齢、OPSの最大値、曲率などの要約統計量を計算しましょう。
library(broom)
regressions <- dj_plot$data %>%
split(pull(., Name)) %>%
map(~lm(OPS ~ I(Age - 30) + I((Age - 30)^2), data =.)) %>%
map_df(tidy, .id = "Name") %>%
as_tibble()
regressions %>%
group_by(Name) %>%
summarise(b1 = estimate[1],
b2 = estimate[2],
Curve = estimate[3],
Age.max = round(30 - b2 / Curve / 2, 1),
Max = round(b1 - b2 ^ 2 / Curve /4, 3)) -> S
S
# A tibble: 9 x 6
Name b1 b2 Curve Age.max Max
<chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Akira Eto 0.882 -0.0213 -0.00247 25.7 0.928
2 Alex Ramirez 0.921 0.0120 -0.00619 31 0.927
3 Hideji Kato* 0.952 -0.00498 -0.00353 29.3 0.954
4 Kazuhiro Wada 0.889 0.0310 -0.00348 34.5 0.958
5 Masayuki Kakefu* 0.875 -0.0586 -0.00678 25.7 1.00
6 Michihiro Ogasawara* 0.975 0.00487 -0.00383 30.6 0.976
7 Nobuhiko Matsunaka* 1.03 0.00420 -0.00713 30.3 1.03
8 Tatsunori Hara 0.921 -0.0166 -0.00364 27.7 0.94
9 Yoshinobu Takahashi* 0.784 -0.0143 0.00174 34.1 0.754
Curveの列が曲率、Age.maxの列がピーク時の年齢、Maxの列がOPSの最大値となっています。
さらにここから、ピーク時の年齢と曲率を散布図で表してそれぞれの違いをわかりやすくします。
library(ggrepel)
ggplot(S, aes(Age.max, Curve, label = Name)) +
geom_point() + geom_label_repel()
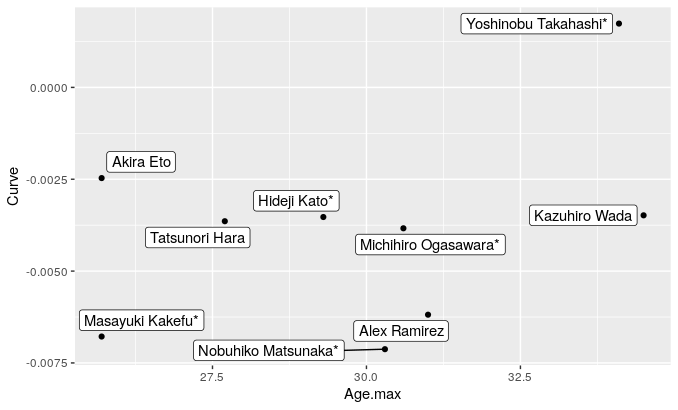
この図を見ることで、高橋由伸選手や和田一浩選手のピーク年齢が後にあったり、掛布雅之選手や江藤智選手はピーク年齢が前にあることがわかります。また、松中選手や掛布雅之選手、Aラミレス選手は曲率の絶対値が大きく、ピークから急激に減衰したことが見てとれます。
まとめ
今回は松中信彦選手を例に挙げて、成績の推移を見ました。また、似た選手を探してピーク時の年齢や成績の推移を比較していきました。
PlayerIDを変えることで他の選手でも行えるので、興味があれば試してみてください。
以前のセイバーメトリクス関係の記事はコチラやコチラもどうぞ。


コメント