

はじめに
こんにちは。
Pythonの機械学習ライブラリと言えば、Scikit-learnやTensorFlowなどが有名です。ただ、前処理の手間であったり、複数のモデルを構築したり、それらを比較するのに時間が掛かったりします。
そこで今回、これらの手間をグーンと減らすことができるPyCaretという機械学習ライブラリを使用してみました。
PyCaretとは
PyCaretは、少ないコードで機械学習で必要な前処理、モデル構築、精度検証、チューニングや可視化などを行うことができる機械学習ライブラリです。
モデル構築や精度検証では、一度にたくさんのモデルを様々な指標で検証することが可能になります。
詳細は公式サイトにありますが、今回はこれを使って少し試してみます。
PyCaretを使ってみる
インストール
インストールはpipから行いました。
pip install pycaret
たくさんのモデルを含んでいるため、インストールには比較的時間がかかりました。
また、ローカル環境のAnacondaでインストールを行った際にはエラーが生じて使用できませんでした。公式サイトにも推奨されているように、Anacondaの仮想環境下でインストールするとうまくいきました。
以前紹介した、Dockerを使用したデータサイエンス環境でも問題なく使用することができました。
データの取得
データはPyCaretにはじめから用意されているデータセットを使用しました。
from pycaret.datasets import get_data
ちなみにデータセットにはClassification、RegressionやClusteringなどの種類がありますが、今回はRegressionのデータセットの中から一つ選んで使用しました。
data = get_data(‘parkinsons’)
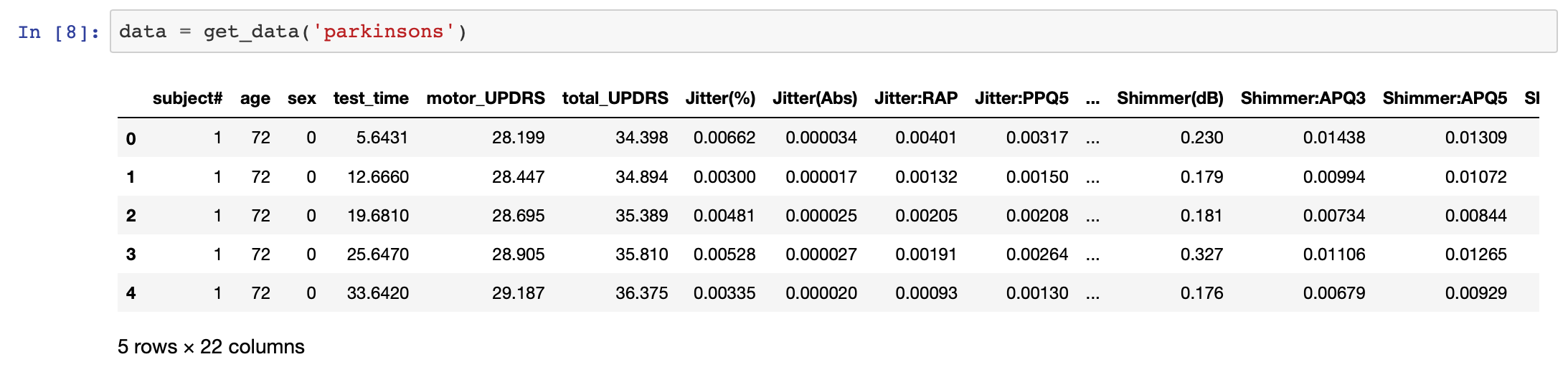
環境のセッティング
Regressionのデータセットを利用したので、Regressionのモジュールをインポートします。
from pycaret.regression import *
それぞれの機械学習の方法によってモジュールのインポートが変わってきます。公式サイトで確認しましょう。
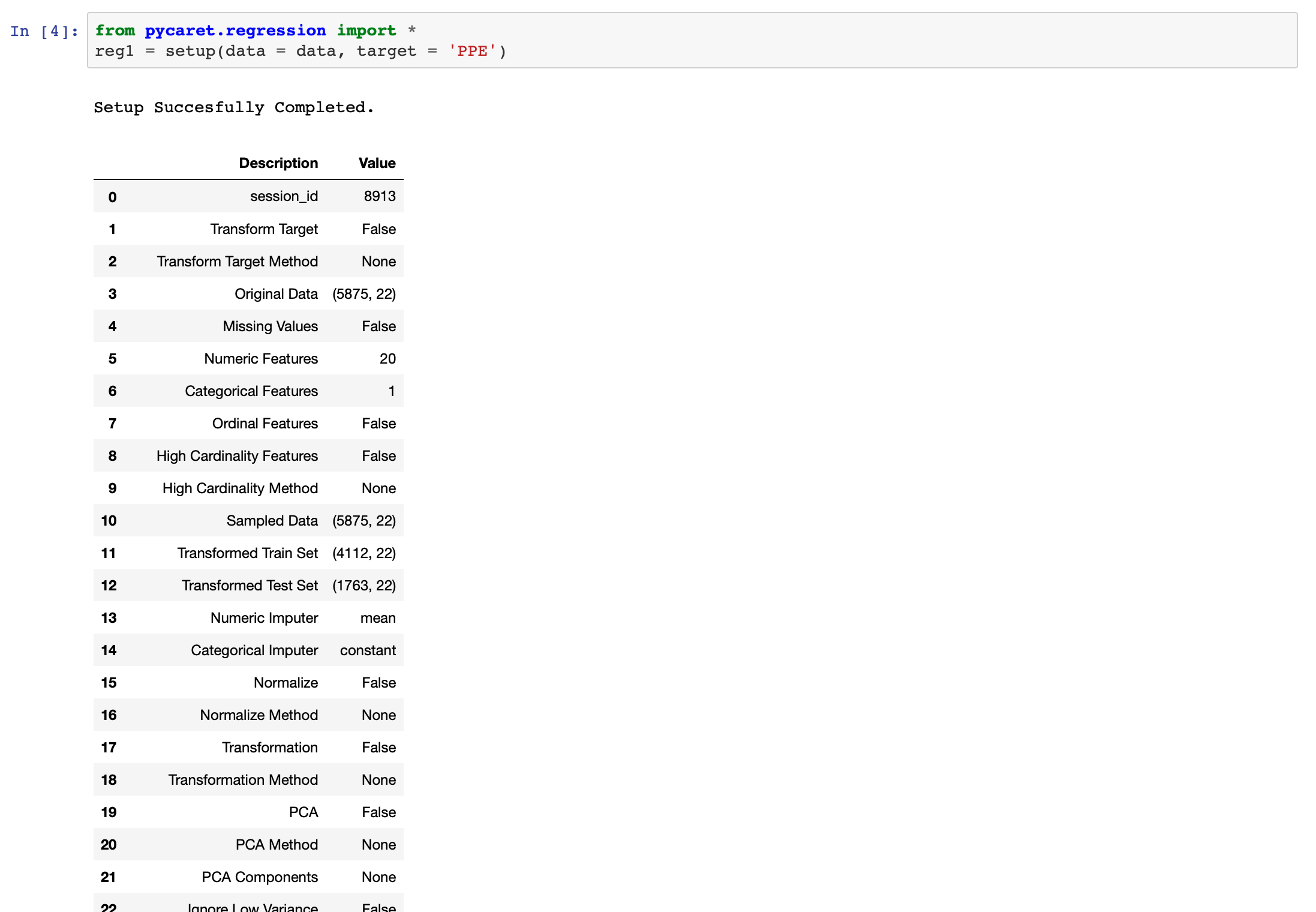
データもモジュールも準備できたら、セットアップを行います。
今回のデータセットのtargetはPPEなので、それもセットします。
regl = setup(data = data, target = 'PPE')
最後に空白のセルが出てきたらenterを押して進めます。
この時にいわゆる前処理をちゃちゃっとしてくれているみたいです。すごいですね!
モデル比較
ここまで来たら、モデル構築をして、それぞれのモデルを比較してみましょう。
compare_models()
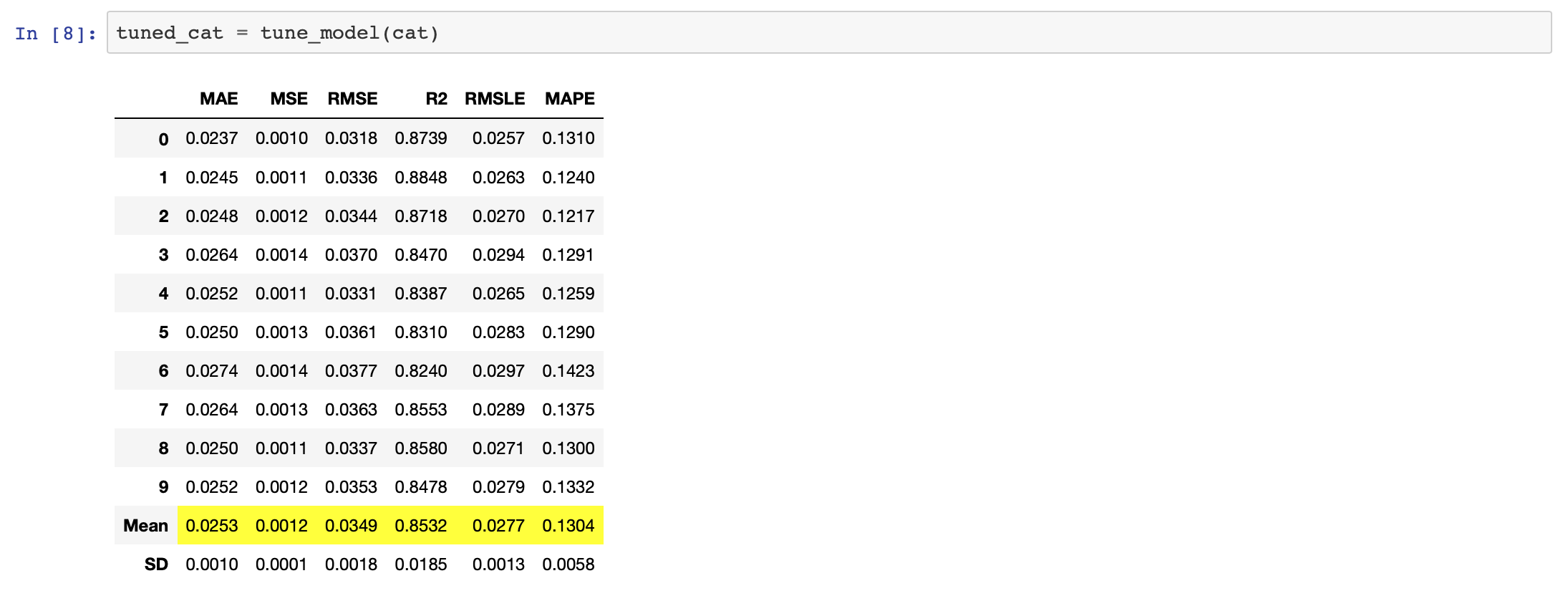
回帰の場合の評価指標はMAE、MSE、RMSE、R2、RMSLE、MAPEで、これらも全て算出し、複数のモデルでの比較を行ってくれます。
その中で、一番良いスコアの物を教えてくれます。
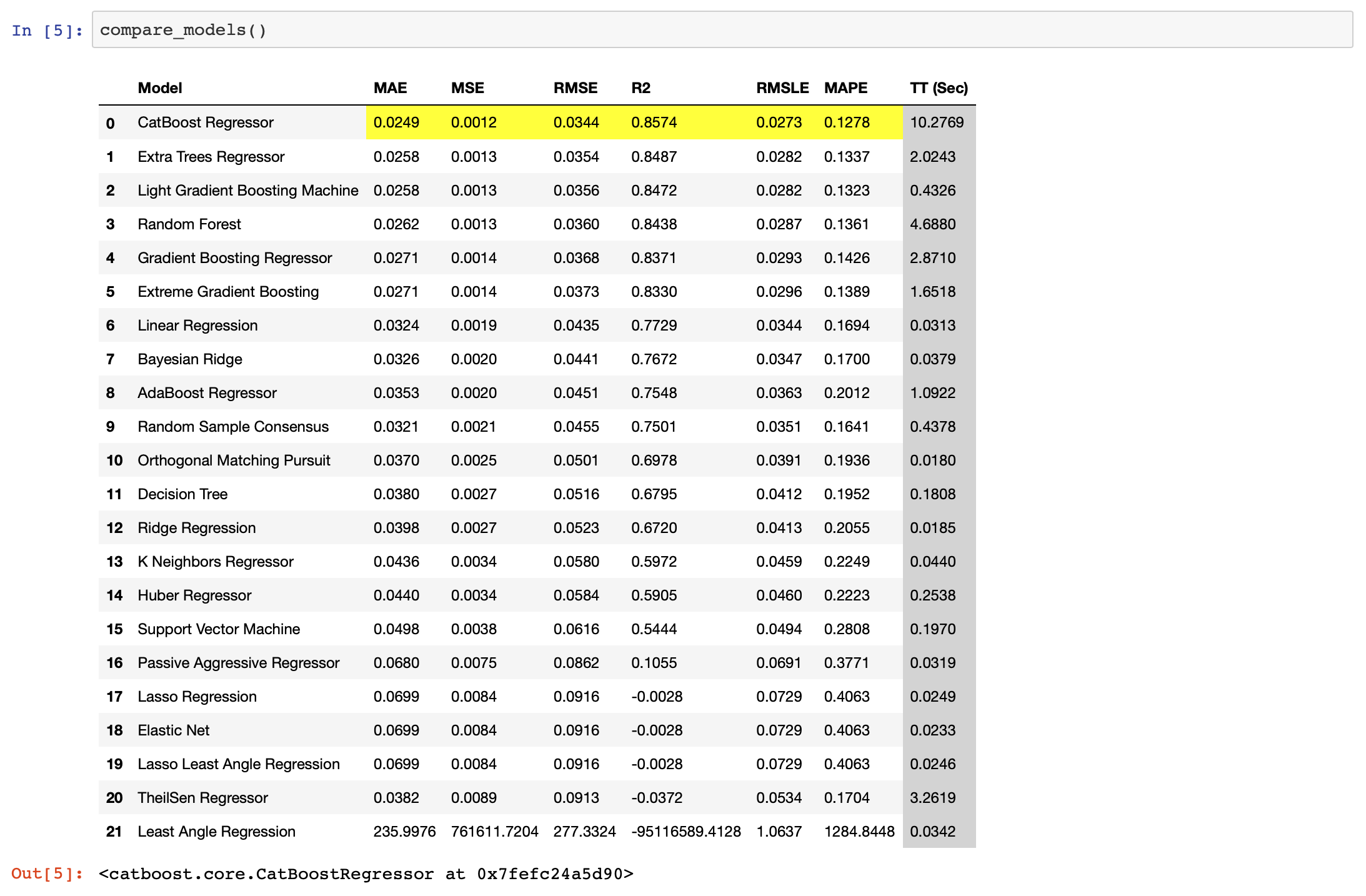
今回はcatboostが一番評価指標の成績が良かったようです。
モデル構築
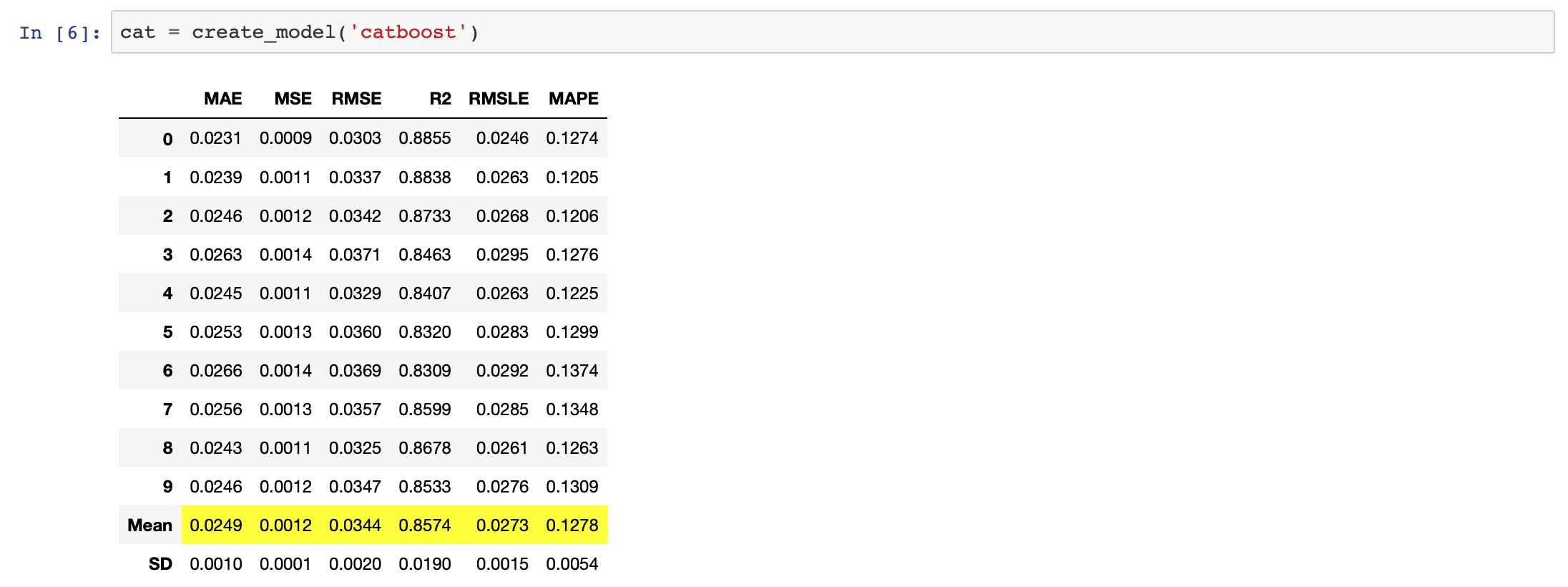
今回は評価指標の成績が一番良かったcatboostを用いてモデル構築を行います。パラメータにはモデルの文字列指定が必要になります。それぞれのモデルの文字列は公式サイトを参照してください。
cat = create_model('catboost')
チューニング
構築したモデルをチューニングしてみましょう。
tuned_cat = tune_model(cat)
可視化
モデルの可視化を行います。基本的にはplot_model()でできるようですが、cat_boostの場合はできず、interpret_model()を勧められました。interpret_model()にはshapが必要だったので、インストール後に行いました。
pip install shap
SHAPに関してはあまり知らなかったのですが、SHAP(SHapley Additive exPlanations)で機械学習モデルを解釈するにわかりやすく書いています。
以下引用します。
SHAPは各インスタンスの予測値の解釈に使えるだけでなく、Partial Dependence Plotのように予測値と変数の関係をみることができ、さらに変数重要度としても解釈が可能であるなど、ミクロ的な解釈からマクロ的な解釈までを一貫して行える点で非常に優れた解釈手法です。
それでも難しいですが、機械学習の場面で言うなら、目的変数に対してそれぞれの特徴量がどのような影響を与えるかを算出する手法だと言えると思います。
実際に可視化したものを見た方がわかりやすいと思いますので、可視化してみましょう。
interpret_model(tuned_cat)
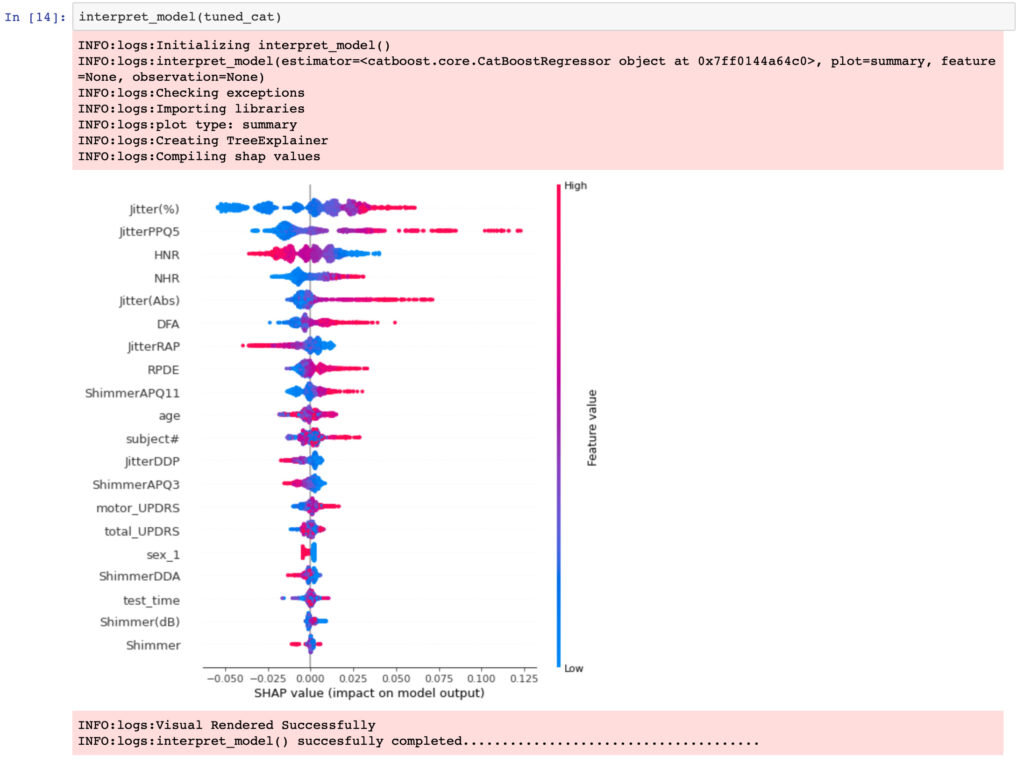
バイオリンプロットのような図が完成しました。
縦軸は特徴量の重要度を示します。重要度は上にあればあるほど重要度が高い(より目的変数に影響を与えている特徴量)といえます。
また、横軸は目的変数の値で、赤は正の値を、青は負の値を示します。jitter(%)の場合は、目的変数が大きく(右側)なるほど赤の分布になり、目的変数が小さく(左側)なるほど青の分布になります。つまり、目的変数とjitter(%)は正の相関があることがわかります。
予測モデル
最後に予測モデルを作成しましょう。
pred_cat = predict_model(tuned_cat)

これで一応一通りのことができました。
コードの行数がとても少ない・・・
すごいですね。
細かく設定をすることで色々できるようですし、アンサンブル学習とかもできるようです。
詳細は公式サイトへ。
まとめ
今回はPyCaretを実際に試してみました。
本当に少ないコードで一連のことができて、すごいなと思います。
データを手に入れて一番はじめに使ってみて、モデルの比較をするとかにはとても使いやすそうですね。
ただ、細かいパラメータなどをしっかり設定したりして使う必要はあるのではないかと思いました。
皆さんも一度使用してみてください。
参考にさせていただいたサイト
PyCaret公式サイト
PyCaret 最小限のコードで最大限のパフォーマンス 機械学習ライブラリ
PyCaret | DataRobotの無料版!?機械学習を自動化するライブラリPyCaret入門
PythonのMLライブラリ、PyCaretを使ってみた
最速でPyCaretを使ってみた
【PyCaret】インストール方法 pipで失敗->仮想環境作成で解決!
SHAP(SHapley Additive exPlanations)で機械学習モデルを解釈する


コメント